2026-06-01
北京时间今日凌晨,曼城女足在温布利大球场以4比0大胜布莱顿女足,时隔六年再次夺得女子足总杯冠军,并成为历史上第三支在同一赛季包揽女足超级联赛和女子足总杯双冠的球队。 ... [详细]
遵守相关法律法规、删帖联系底部客服
|
编辑|杨文 在编程Agent的评估领域,一直存在着难以精准衡量的困境。 当下,SWE-bench已然成为业界公认的事实标准。几乎每一家推出新模型或者新Agent框架的机构,都会亮出SWE-bench的分数,以此彰显自身实力之强劲。 然而,这些分数真的能够毫无偏差地进行横向对比吗? 从本质上来说,LLM Agent的能力是由模型和harness共同塑造的。同一个模型,若搭配不同的harness,在SWE-bench、Terminal-bench等评测中的分数,可能会出现十几甚至二十多个百分点的巨大差异,这种差距甚至堪比更换一代模型所带来的影响。 也就是说,一个SWE-bench分数的背后,实际上隐藏着三个关键变量:底层所运用的大模型、将大模型转化为Agent的harness设计方式,以及评测所采用的任务批次。 以SWE-agent、AutoCodeRover、OpenHands、mini-SWE-agent等系统为例,每个系统都拥有独特的提示词模板、工具接口、最大轮数、超时策略以及停止逻辑。模型、harness、任务集这三个变量相互交织,当A系统比B系统高出几个点时,我们很难判断这究竟是模型性能更优、harness设计更为出色,还是任务集的选择更具优势。 另一方面,像OpenClaw这类原本面向通用工具调用场景的Agent,根本无法进入SWE-bench的评分流程。这就导致“通用Agent是否具备写代码能力”这一问题,长期处于无法有效验证的状态。 近日,基元律动联合无问芯穹,以及清华大学、北京大学、SEE基金等机构共同发表了一篇论文,并且将代码和数据完全开源,试图为编程Agent的评测难题找到清晰的解决方案。
论文提出了一套claw for coding适配器,首次让OpenClaw这类通用Agent能够在SWE-bench式的真实代码任务中提交可评分的成果。 基于这套适配器,他们构建了Claw-SWE-Bench,这是一个涵盖8种编程语言、43个真实代码仓库、350个GitHub issue修复任务的多语言基准,同时还为学术圈和小团队提供了一个轻量版Lite-80。 该基准强制要求所有系统在统一的提示词、预算和评分流程下,汇报API总成本,使得准确率和运行代价能够在同一张表格中直接呈现,便于解读。 这也是在SWE-bench式基准中,首次将harness作为可独立测量的变量进行控制 在搭建评测环境的过程中,他们还意外发现并修复了SWE-Bench-Multilingual官方数据集中存在的一处答案泄露问题,并且已经向上游提交了修复请求。 基元律动由原华为诺亚方舟实验室主任、盘古大模型负责人王云鹤创立,他在离职仅两个月后就完成了首轮融资。 Claw-SWE-Bench正是其首个对外展示的技术成果。 适配器究竟解决了什么问题? OpenClaw这类通用Agent,主要面向的是更为广泛的工具使用场景。它具备调用工具、读写文件、执行命令、保留会话状态以及生成自然语言解释等多种能力。 然而,在SWE-bench的评分体系中,系统必须提交一个可应用于代码仓库的diff patch,评估器只关注patch和测试结果,对于自然语言回答和Agent的交互轨迹则完全不予考虑。这种差异源于测评方式本身的局限性,并不能真实反映Agent的实际能力。 这种差异带来了几个直接问题。 其一,SWE-bench需要一个干净、可复现的Docker工作区,而通用Agent则依赖于自身的运行环境、工具配置、API访问以及会话状态。 其二,SWE-bench只读取model_patch字段,而通用Agent原生输出的可能是最终回答、结构化消息或者日志。 其三,通用Agent在执行过程中可能会生成各种缓存、元数据、会话文件,一旦这些内容混入git diff,就会污染最终提交给评估器的patch。 因此,OpenClaw无法原生进入SWE-bench评分流程,并不意味着它不具备写代码的能力。更准确地说,是我们需要将通用Agent的行为转化为SWE-bench能够读取、应用和评分的标准化内容。 Claw-SWE-Bench的解决思路是引入一个adapter(适配器)层 OpenClaw式harness与SWE-bench之间存在不匹配的情况。适配器能够将通用Agent的交互转换为可由SWE-bench评分的补丁预测,同时通过外部控制确保评测的公平性、可比性以及成本的可追踪性。 不同harness通过统一接口接入评测流程,Agent无需在最终回答中手写diff,而是在/testbed工作区中真实编辑仓库文件。运行结束后,runner从Git状态中导出代码补丁。 为了验证这套适配器是否真的有效,研究者进行了一组bare adapter和full adapter的对照实验 同样以GLM 5.1为底层模型,在全部350个实例上,bare adapter仅进行最小集成,将OpenClaw放入Docker环境,发送任务描述,然后让模型直接在最终回复中输出一段unified diff文本。结果显示,bare adapter的Pass@1仅为19.1%,patch应用失败率高达69.1%。 而full adapter则要求Agent通过工具直接编辑仓库文件,再由runner从Git状态中导出代码补丁。此时,Pass@1提升至73.4%,应用失败率降至1.5%以下。 这也表明,一个通用Agent可能已经具备解决代码任务的潜力,但如果缺少合适的评测接口,其能力可能会被patch格式、工作区污染、输出解析等工程细节所掩盖。而适配器本身就是释放能力的重要环节。 一个多语言基准的诞生 在适配器的基础上,研究者构建了Claw-SWE-Bench,以此解决“评什么、怎么评得公平”的问题。 完整版本的Claw-SWE-Bench包含350个真实的GitHub issue修复任务,覆盖8种编程语言、43个代码仓库。其中,300个非Python实例来自SWE-bench-Multilingual,涵盖Java、Go、Rust、JavaScript/TypeScript、C/C++、Ruby、PHP;另外50个经过人工校验的Python实例来自SWE-bench-Verified-Mini。 为了让不同harness之间的差异能够真正可比,Claw-SWE-Bench在外层固定了一套评测条件。所有harness使用同一份提示词模板、同一个任务集、同一套Docker运行环境,以及每个实例相同的3600秒超时预算。 提示词中的任务描述、操作规则完全一致,差异仅来自harness自身的内部实现。 如此一来,不同harness之间的Pass@1差异,才能真正归因于harness设计,而非外部条件不同所造成的假象。  由于完整版本包含350个实例,这样的评测规模成本过高,适合正式报告,但不适合日常高频迭代。 为此,研究者还构建了一个轻量版本Claw-SWE-Bench Lite,从8种语言中各选取10个实例,共80个实例,专门提供给学术团队、开源社区和资源有限的小团队,用于日常的提示词调整、模型替换、适配器调试和回归测试。 Lite版本并非随机抽样,它控制了语言分布、难度四分位和仓库覆盖,并以17个校准列拟合full-350的行为,这17个校准列同时覆盖模型变化和harness变化。 结果显示,Lite-80的成本约为full-350的22.9%。在17个校准列上,full-350平均Pass@1为0.639,Lite-80为0.643,仅相差约0.4个百分点。 Lite-80与full-350的一致性。(a)full-350与Lite-80在各语言上的Pass@1对比,结果是在17个校准列上均匀平均得到的。(b)在5种claws × 2个共享模型上,full-350与Lite-80的跨claw Pass@1对比。(c)K扫描的敏感性包络;在不同情景下,最小可接受K值落在[8, 10]区间内,发布版本采用保守且稳定的K = 10,即每种语言10个实例。 Lite版本还覆盖了full-350中43个仓库里的34个,覆盖率达到79%。 花费约四分之一的成本,就能获得与完整评测几乎一致的反馈信号,这对于学术团队和小公司来说非常友好。 此外,在构建这套多语言任务集的过程中,团队还发现了一个问题。 在检查SWE-bench-Multilingual的容器时发现,部分实例中base_commit之后的Git历史仍然可见。如果Agent通过git log或git show看到未来的修复提交,分数就会被人为抬高。 因此,研究团队在非Python多语言任务中移除了base_commit之后仍可达的Git历史,并将这一清理逻辑纳入Claw-SWE-Bench评测流程的标准步骤,同时将这一问题反馈给了上游SWE-bench-Multilingual项目。 清理之后,9个模型在300个Multilingual实例上的Pass@1没有一个上升,Claude Opus 4.7下降最多,从84.7%降到76.7%,降幅达8.0个百分点;Kimi 2.6下降5.0个百分点,Qwen 3.6-flash下降2.0个百分点。 两组横扫实验,深度剖析关键变量 在统一的适配器和评测协议下,论文进行了两组横扫实验。 固定harness,更换模型 第一组实验固定OpenClaw这个harness,仅更换底层模型,在9个模型上进行横扫。 结果显示,模型选择依然起着关键作用。GPT 5.5表现最佳,Pass@1为78.0%,Claude Opus 4.7为77.1%,GLM 5.1为73.4%,最低的Seed 2.0-mini为48.6%。最高和最低之间相差29.4个百分点。 这组实验真正引人深思的结论在成本方面。GPT 5.5完成350个实例的总API费用为1399美元,Claude Opus 4.7为1082美元,两者Pass@1相差不到1个百分点。 DeepSeek-V4 Flash以70.3%的Pass@1完成评测,总成本仅需8.2美元。DeepSeek-V4 Pro以71.7%的成绩花费81美元,Qwen 3.6-flash以66.0%花费71美元。 同样是七成左右的解决率,成本却可能相差两个数量级。如果评测报告仅提及Pass@1,完全无法体现这一维度的差异。 固定模型,更换harness 第二组实验则固定模型,在GLM 5.1和Qwen 3.6-flash上分别对OpenClaw、Hermes-agent、ZeroClaw、GenericAgent、Nanobot这五个harness进行横扫。 提示词、任务集、运行预算等其他条件全部保持一致,唯一的变量就是harness内部的agent loop、工具集和停止策略。 结果显示,在GLM 5.1上,五个harness的Pass@1分布在60.9%到73.4%之间,差距达12.5个百分点。 在Qwen 3.6-flash上,从Generic的38.6%到OpenClaw的66.0%,差距扩大到27.4个百分点。 Claw维度的变化:五种claws × 两个模型在完整350实例Claw-SWE-Bench上的结果。Cost表示完整运行的总API成本(美元);In/Out表示总输入/输出token数(百万);Cache表示缓存命中率。在每个模型组内,最佳Pass@1和最低Cost以粗体标出。 同一个模型,更换一套harness,结果可能相差一个模型档位甚至更多,这说明在编程Agent中,harness会显著影响最终能力 论文进一步使用Pareto前沿图展示了成本分布情况。 横轴是350个实例完整运行的总API成本,纵轴是Pass@1,Pareto曲线连接那些“没有任何其他组合既更便宜又更准确”的工作点。 可以看到,generic × Qwen 3.6-flash成本最低,约14.5美元,但Pass@1只有38.6%,实用价值有限。 ZeroClaw × Qwen 3.6-flash花费49美元可达58.3%,OpenClaw × Qwen 3.6-flash花费71美元能到66.0%,OpenClaw × GLM 5.1花费277美元可达73.4%。 这类对比将评测从“谁分数最高”推进到“什么组合在成本和准确率之间最值得选用”。对于研究团队、开源社区和小公司来说,这个视角尤为重要。真实研发通常并非一次性冲榜,更多时候是在预算约束下反复试错、调参、回归和验证。 结语 AI编程Agent的竞争,已不再仅仅局限于模型层面。真正决定其能否融入真实软件工程流程的,还包括工程实现、系统架构和成本控制等因素。 然而,在当前以单一Pass@1数字为核心的行业话语体系中,这些维度几乎被忽视。 一个系统分数更高,究竟是因为模型更强、harness设计更好,还是任务集选得更有利,外界往往难以分辨。 因此,未来的编程Agent评测,不能仅仅报告Pass@1,也不能默认将所有提升都归因于模型。harness设计、工具接口、运行预算、缓存策略与成本核算,都应当纳入评测范畴。否则,我们所看到的数字,最多只是故事的一半。 |
 26/27赛季巴萨首笔重磅转会:卡萨多或将永久离队
26/27赛季巴萨首笔重磅转会:卡萨多或将永久离队  山东姑娘张子宇:场均10分钟轰11分,宫鲁鸣盛赞却难掩战术困境
山东姑娘张子宇:场均10分钟轰11分,宫鲁鸣盛赞却难掩战术困境  北京之夜:马斯克库克中间的56岁中国女性,低调背后的传奇人生
北京之夜:马斯克库克中间的56岁中国女性,低调背后的传奇人生  F1巴塞站勒克莱尔换刹测试显成效 法拉利升级包初露锋芒
F1巴塞站勒克莱尔换刹测试显成效 法拉利升级包初露锋芒  2026NBA选秀格局重塑:奇才押宝全能锋线 爵士灰熊组建双塔
2026NBA选秀格局重塑:奇才押宝全能锋线 爵士灰熊组建双塔  NBA扩军新动向:五座城市或迎新球队,篮球版图再扩张
NBA扩军新动向:五座城市或迎新球队,篮球版图再扩张  射击世界杯西班牙站:王子菲/盛李豪气步枪混团摘金,姚千寻/胡凯气手枪混团获银
射击世界杯西班牙站:王子菲/盛李豪气步枪混团摘金,姚千寻/胡凯气手枪混团获银  上海男篮赛点战在即,卢伟防守策略奏效,北京双后卫受困,赵睿亟待爆发
上海男篮赛点战在即,卢伟防守策略奏效,北京双后卫受困,赵睿亟待爆发  惊人巧合!连续两年交易得浓眉球队皆获状元签
惊人巧合!连续两年交易得浓眉球队皆获状元签  穆里尼奥:从对抗到建设,狂人执教哲学的华丽转身
穆里尼奥:从对抗到建设,狂人执教哲学的华丽转身  CBA季后赛|山东队客场虽败犹荣,上海队险胜仅5分
CBA季后赛|山东队客场虽败犹荣,上海队险胜仅5分  进攻低迷!魔术控卫萨格斯遭76人全面压制,生死战能否反弹?
进攻低迷!魔术控卫萨格斯遭76人全面压制,生死战能否反弹?  CBA总决赛上海2-0领先:古德温绝杀定乾坤,胡金秋里程碑超越王治郅
CBA总决赛上海2-0领先:古德温绝杀定乾坤,胡金秋里程碑超越王治郅  郑钦文鏖战2小时18分逆转邦达尔 WTA罗马站首轮上演惊天翻盘
郑钦文鏖战2小时18分逆转邦达尔 WTA罗马站首轮上演惊天翻盘 
2026-06-01
北京时间今日凌晨,曼城女足在温布利大球场以4比0大胜布莱顿女足,时隔六年再次夺得女子足总杯冠军,并成为历史上第三支在同一赛季包揽女足超级联赛和女子足总杯双冠的球队。 ... [详细]

2026-04-12
一人扛着全队前进,球队却要把他的纪录梦一起埋了。一、14球,一个人撑起整个皇马的欧冠先把数据甩出来,让你感受一下姆巴佩这赛季在欧冠到底有多炸裂。截至欧冠1/4决赛首回合,姆 ... [详细]

2026-06-09
6月8日,山东男篮夏训集结,邱彪进行首波人员调整,于德豪、孙桐林等四将离队,球队阵容更新换代正式拉开序幕。 ... [详细]

2026-06-13
公元1367-1370年,汉萨同盟对丹麦发起首次贸易战争,奠定北方霸主地位,揭示地缘经济法则:掌控供应链者更强。本文深度剖析战争背景、过程及影响。 ... [详细]

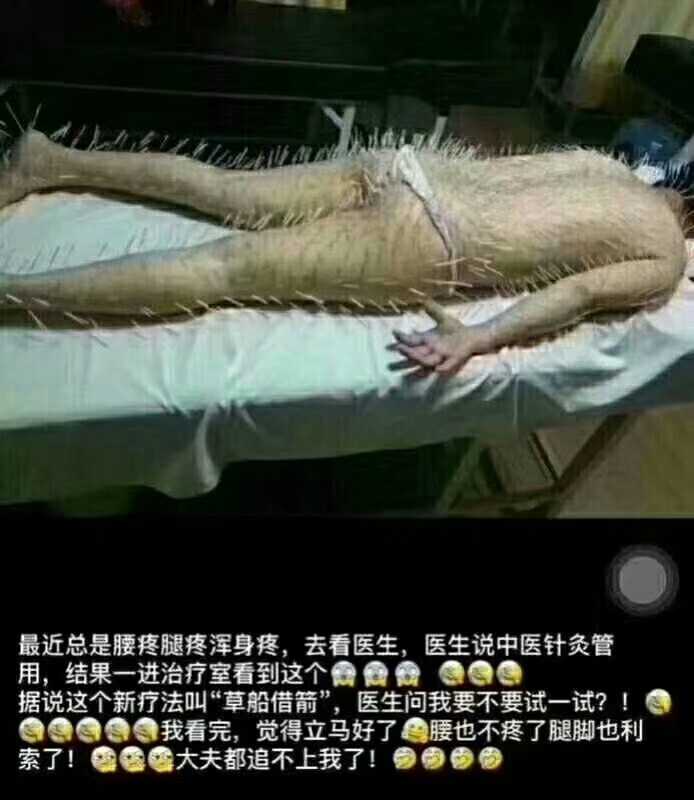
啥病人看了这个都得好啊! 副标题 这胸是真的! 副标题 你赢了! 副标题 我是关心这是在哪里

乞丐装的最新境界! 副标题 买家你确定你不是阿宝?? 副标题 这裤子不敢坐下啊! 副标题 颜值
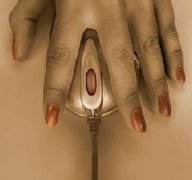
这鼠标垫你看到了什么?邪恶了吧! 副标题 毫无违和感! 副标题 小卖部的这女孩真会选呀! 副

女人真的不容易,怀孕后,内脏被挤压的严重,挺着大肚子干啥都不方便!近日,刘嘉姵和闺蜜集体拍

锤哥的替身也是辣么的帅气! 副标题 锤哥的替身好多啊! 副标题 你杀了你的替身,你可就没替

喜当爹虽然和恭喜当爹就差一个字,但是意义可是差了十万八千里,当然这个词也是因为一个特

中国历史上有很多著名的寺庙,比如说白马寺、寒山寺、灵隐寺等,其中寒山寺和灵隐寺因为地

折耳根是一种在南方很常见的植物,北方人可能很少人知道折耳根是什么。下面就让我们先来








